
This article is the first of a two-part series on genomic data, privacy and emerging cybersecurity threats. Part one details key issues affecting genomic data and technology challenges. Part two offers an “additive” model to current regulations on genomic data to provide further protections, along with key recommendations that include adoption of a higher standard of security and privacy protection. Part two will be published in Issue 4 of Health21 magazine, released November 2017.
Advances in privacy and security must occur in parallel with advances in medical science. Medical science, however, often moves at a faster pace than cybersecurity experts’ ability to appropriately analyze those advances, thus resulting in gaps that can have significant implications for health information protection. Such is the case with genomic data. Specifically, the 2008 Genetic Information Nondiscrimination Act (GINA) requires modification to the 1996 Health Information Patient Protection Accountability Act (HIPAA) to include genomic data as protected health information (PHI). This inclusion is beneficial; however, simply categorizing genomic data as PHI is insufficient. Protections afforded PHI under HIPAA do not consider multi-generational implications, informed consent, breach notification or other material issues, if data is breached. In short, genomic data requires a higher level of protection than traditional PHI.
Overview
Technology has allowed for rapid advancement of medicine and is now taking humanity to an unprecedented level of personalization, called “precision medicine.” This “emerging approach for disease treatment and prevention takes into account individual variability in genes, environment and lifestyle for each person” [1]. Advanced understanding of the human genome and a person’s genetic makeup/profile can lead to specific treatments for many genetic-based diseases (i.e., cancer), with treatment personalized to the individual.
Many promises to advance patient-powered research exist under the aspect of precision medicine, with the White House allocating $215 million to the administration’s 2016 budget to support this initiative. The Journal of the American Medical Informatics Association (JAMIA) recently addressed the future direction of electronic health records (EHRs), stating: “. . . with ever-decreasing costs of sequencing technology, patients’ genomes are likely to be sequenced routinely in the course of clinical care in the not-so-distant future” [2].
Although promises of advancement for precision medicine are grand, so are the challenges. One such challenge rests with security and privacy of genomic data. The White House published Precision Medicine Initiative: Data Security Policy Principles and Framework [3], which is beneficial for users adopting the Precision Medicine Initiative (PMI). However, it does not adequately address specific security and privacy challenges that genomic data presents to PMI.
The information presented is intended to be additive to the White House PMI and National Institute of Standards and Technology (NIST) Frameworks by presenting an additional model with a specific focus on security and privacy risks of introducing the human genome into the current electronic healthcare record. A new model for cybersecurity and privacy will be introduced, which will provide a comprehensive framework for consideration within precision medicine.
For precision medicine to reach its full potential, the healthcare team requires access to the patient’s current healthcare information in addition to the ability to access new tools, knowledge and therapies. Those therapies are intended to be personalized and, therefore, require specific human genome sequencing. A person’s human genome will need to be shared across a broader spectrum of professionals, expanding the healthcare team to include geographically disbursed researchers, clinicians and other professionals involved in creating personalized, specialized treatment protocols and therapies. This increased sharing of healthcare data in cyberspace, including genomic and phenomic data[1], exacerbates cyber attack vectors. The latter includes insider threats, hacktivists, organized crime, nation states and substandard products and services obtaining expanded and highly valuable data sets.
Following either the White House PMI or NIST Framework will assist with risk mitigation. However, it does not fully address the protection of human genome challenges compromising confidentiality, integrity and availability (CIA) of the new healthcare data set.
A repeated caution is noted: The model provided is intended to be additive to current policies and practices already recommended for genomic data. It enhances privacy and security, as genomic data is more sensitive than traditional PHI. It does not, as no model can, provide absolute assurance that a breach or violation will not occur by implementing these enhanced recommendations. It does, however, ensure that if these recommendations are followed, further protections will be provided for genomic data above current industry practices.
Regulations Protecting Genomic Data
Genomic data faces a bifurcated set of concerns. First, policy and ethical concerns are still playing out in several legal cases and in the court of public opinion, which will shape regulations on how genomic data must be protected. Since several federal agencies, including Centers for Medicare and Medicaid Services (CMS), National Institutes of Health (NIH) and Food and Drug Administration (FDA), exercise jurisdiction over clinical testing, including genetic testing, stakeholders will see enhanced regulatory requirements going forward, namely security/privacy of genomic data.
Currently, many laws exist regarding genomic data and how it must be protected. HIPAA includes genomic data as PHI [5], so it must be protected to meet all privacy and security requirements comprised within HIPAA legislation. The authors argue that more stringent controls are required. GINA provides provisions for protecting individuals from genomic discrimination from employers and health insurers. However, it is lacking in security and privacy provisions. The 2002 Federal Information Systems Management Act (FISMA) protects federal systems and ensures security and privacy controls are in place to protect HHS agency systems (Veterans Affairs, NIH, CMS, Centers for Disease Control and Prevention, etc.) that store genomic data. FISMA also points to NIST Special Publications 800 series for further security and privacy control directives for protecting bioinformatics systems storing genomic data.
From a policy perspective, the federal government (i.e., NIH, NIST, HIPAA [Privacy/Security Rules and Omnibus], White House directives) has established policy around genomic data protection, which is welcomed and that provides substantive recommendations for security and privacy. State regulations around genetics laws must also be considered and can be found here for reference purposes. Although the site is not kept current, further reference is required when handling genomic data in any given state. State-specific restrictions on using genetic information can be found here. The authors also believe these collective documents do not provide sufficient diligence in describing how to protect genomic data. Therefore, information provided here adds to the current literature with additional rigor for those handling such data.
Privacy of Genomic Patient Data
Genomic files are one of the last frontiers to be exposed to PHI and data privacy. Unlike traditional PHI data, which typically refers to one patient or an individual, in-depth genomic data and DNA sequencing files are specific to a human and family line for generations, thereby requiring more advanced considerations for protection. Genomic data not only identifies the patient but also the patients’ family and its multiple generations.
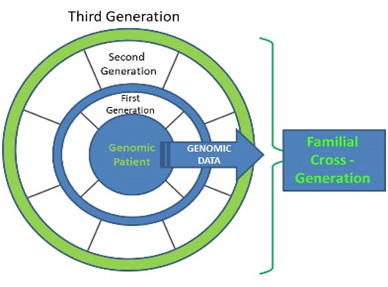
Figure 1: Genomic Privacy Across Generations
Figure 1 depicts the individual patient and associated generations spiraling out where the genomic data is relational to first, second, third and future generations. Of primary concern, one can identify not only the patient with genomic data but also his/her entire family line with specific genomic traits for generations.
Due to generational implications, genomic data warrants the highest level of privacy protection and, at this point, no expiration exists for its protection. Given its familial cross-generational characteristics, genomic data must be protected beyond an individual’s lifetime, quite possibly for generations. Therefore, HIPAA privacy/security rules need to be reviewed for longevity requirements for protecting genomic data.
Issues Affecting Genomic Security
Privacy. Individual genomic information contains sensitive medical and birth lineage information. The intent of precision medicine is to add genomic data to the electronic health record to personalize medical treatment. This data can depict a patient’s disposition to being a carrier of a gene that can be disease-causing [7]. Therefore, this information is incredibly sensitive to patient and family.
Prior to precision medicine advances, genomic privacy considerations were not addressed as part of the continuum of care. As precision medicine make strides and million of patients share their genomic data with their providers, and that data is stored in EHRs, a serious ethical question arises regarding the nature of in-depth genomic data and privacy requirements to protect this data. Another consideration is evolution of genes from generation to generation – meaning genes can change due to mutations or environmental factors, and these genomic variances require privacy protections as well.
Case in point, Great Britain’s Queen Victoria carried the hemophiliac gene, which eventually led to her great grandson and others having hemophilia. Figure 2 depicts royal family members who inherited the hemophilia gene, women who carried the gene and male members diagnosed with hemophilia.
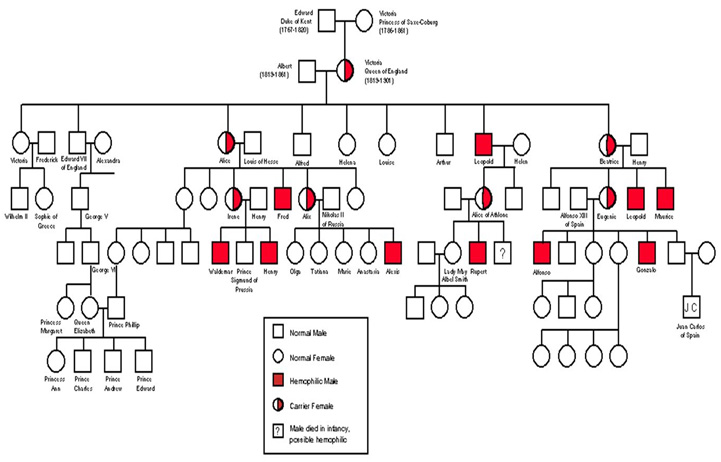
Figure 2 Queen Victoria Genomic Bloodline for Hemophilia
Diagram created by National Center for Case Study Teaching in Science, University of Buffalo at http://www.emersonkent.com/source_documents/victoria_hemophilia.htm [8]
As Figure 2 illustrates, genetic disposition of a family continues from generation to generation. It is extremely important to treat genomic data with the correct safeguards to protect both the patient’s health information and his/her family data and generational record, known as a pedigree record.
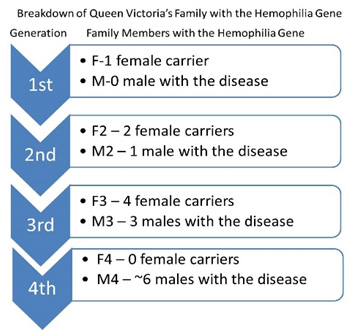
Figure 3 Hemophilia Bloodline Genomic Summary
Figure 2 depicts all family members, including which members carried the gene. Figure 3 further breaks down actual members who either carried the hemophilia gene or had hemophilia quantitatively. Figure 3 also shows the hemophilia gene spanning more than four generations, with seven females carrying the gene and more than 10 males having the disease. This historical example illustrates how genomic data and family history is relevant to families for multiple generations and warrants additional protection to all people involved.
The Internet. At first, it was thought deidentification[2] was the Holy Grail for genome data, thus leading to perhaps a more lax focus on security. However, “in a recent study, researchers were able to reidentify research participants using the publicly available deidentified personal genome data and other publicly available metadata” [6]. Given the far-reaching implications of the Freedom of Information Act (FOIA), much government information is publically available and, therefore, FOIA holds a spot in the law category affecting genome data privacy. The deidentification example is representative of the need for larger scale security measures encompassing current regulations mentioned (i.e., HIPAA, FISMA, etc.), as well as policy drivers like NIH and the White House.
In a Harvard/MIT study, researchers determined individuals can “genotype their Y-chromosome haplotypes” to identify familial and patrilineal relatives. This includes identification of people who anonymously donated their DNA. Anonymous genomic data can be cross-checked using online genomic genealogy databases and then be re-identified with the original genomic anonymous owner. This process is called reverse identification of genomic data. This strategy is very similar to the Sweeney attack, where minimal information is needed to re-identify a person. The Harvard/MIT study proved the same with anonymous genomic data being re-identified from its original source with use of minimal data (e.g. metadata, age and state).
Genomic privacy violations have very distressing implications to patients and families should their detailed data be stolen and exposed. In some cases, exposure of genomic data can cause maternity or paternity family issues and problems. In addition, data exposure could potentially cause decades of familial discrimination, harassment and blackmail. It is a hope that the model presented in this research will inform national and local policy and be considered further for securing genome data going forward.
Discrimination. Growing concerns exist regarding genomic data being used for discrimination. As already addressed, genomic data not only encompasses an individual but also his/her family. Scholars and lawyers have articulated concerns about genomic data being used in a negative capacity. Even with GINA, a law created to prevent medical insurance and employment discrimination, people can still be victimized by genomic discrimination. Furthermore, GINA does not cover life insurance, disability and long-term care disability; it only covers medical insurance and employer discrimination.
From a discrimination perspective, another concern is genomic data getting into the wrong hands. For example, a health or life insurance company would want to know a person or family’s disposition to disease and/or chronic health issues from genomic data in order to determine risk and eligibility for a person or family line. The insurance company could use the genomic data to discriminate against potential policyholders.
Not only can genomic data be used for discrimination but also industrial espionage, especially with respect to hacking genomic data, which will occur in a matter of time. Theft of genomic data from a competitor, or for unethical purposes, will mostly be for financial gain. The dark web certainly will have nefarious actors and state sponsors highly interested in exploiting a genomic database for financial gain, maleficent activity and discrimination, thereby making genomic data privacy and security an increasing issue.
Minimum Use. Within HIPAA, “minimum use” is a term referring to a security and privacy requirement allowing only the minimum information necessary for treatment, payment and healthcare operations. Minimum use could come into play for bioinformatics systems with genomic data and EHR systems. Genomic files certainly contain a plethora of genetic data that will require reduction in order to store only minimum use information in an EHR system. Genomic bioinformatic systems need to adhere to the minimum use rule.
Supply Chain. Through precision medicine, the genomic supply chain will have to be closely monitored for both physical and personnel security. This will include, at a minimum, genomic counselors, genetic testing services and centers, genome interpretation services, laboratories, hospitals, individual doctor offices, bio banks, academic institutions and government projects, such as NIH. Any one of these supply chains can be exploited where genomic data could be exfiltrated and exposed. Therefore, these stakeholders must be evaluated and appropriate contractual agreements put into place to protect genomic data. This includes business associate agreements, non-disclousre agreements, data use agreements and more. This has special implications for laboratories collecting genomic data and medical practices utilizing the results within the precision medicine lineage.
Personnel Security. Personnel security is of paramount concern for organizations that have staff handling genomic data. Individuals will have to be properly vetted for employment to ensure they do not put genomic data at risk through unlawful exposure, theft or espionage. Customized HIPAA training will need to be provided to cover genomic data protection, as most HIPAA training does not include this material. Personnel handling genomic data will be required to encyrpt genomic files when genomic data is in motion and at rest.
Genomic Technology
Modernization. Genomic files require modernization so data can be parsed to a database rather than stored in a huge file (SAM/BAM/VCF, or PDF file). At this time, genomic data technology is based on scientific and research bioinformatic needs and has limited output capabilities. As genomic data becomes mainstream for PMI, information technologists will start to develop more feasible means to view and to share genomic data. As this occurs, security and privacy considerations will need to be overlaid to new capabilities to ensure new risks or access points are not introduced. With every system change, a Security Impact Analysis (SIA) should be conducted.
Integration. Current EHR systems are not equipped for clinical use of large genomic files, and EHR servers cannot handle current genomic file sizes without additional capacity planning. As precision medicine increases, EHRs will have to accommodate genomic data and integrate it into their legacy systems. Sizing issues could occur with system hard drives lacking space for these large files and network degradation issues resulting from staff accessing and using genomic files.
In addition to integration issues, current staff (doctors and nurses) are not fully conversant in reading genomic files. A learning curve will be required for staff to become educated on how to read and use genomic data. In the interim, lack of knowledge will increase risk because staff will not know what to protect from genomic data introduced into the EHR system in regards to input and output. Several hospital projects are currently launching precision medicine, so EHR systems are being retrofitted or replaced to incorporate genomic data. This introduces another risk as legacy EHR systems are frequently insecure; incorporating genomic files into insecure legacy systems further exacerbates HIPAA concerns.
Genomic Data Files. Genomic files (SAM/BAM/VCF) are large files, and a cyber criminal could use this to their advantage in crafting distributed denial of service (DDOS)[3] attacks causing confidentiality, integrity and availability (CIA) issues. Table 1 depicts genomic files, their function and average file size.
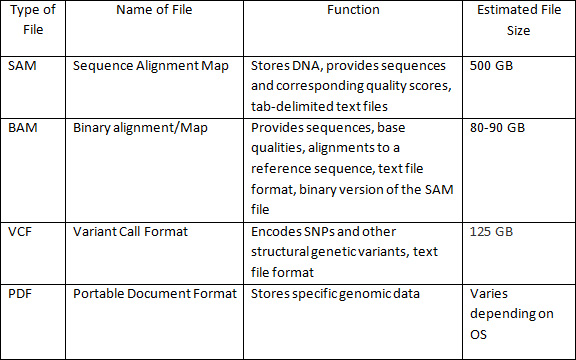
Table 1: Genomic File Sizes and Function
In architecting a PMI system, considerations must be addressed for network and storage in dealing with large genomic files. The size of collective genomic data provides concerns when moving from the sample (i.e., saliva, blood, hair, etc.) to biologically and/or medically relevant digital information. The ability to access this data remotely is limited by network and storage capabilities. Issues with accessing data directly impacts CIA of the data, making it a significant security concern and, therefore, substantiates the need for an additive model to protect genomic data.
Another concern is genomic analysis based on a single genomic file or dual/tri analysis. As mentioned, genomic files are large to begin with, so ample processing power is a must, if multiple analyses is required. Current EHR systems, servers and computers may not have the processing power needed for dual analysis, thus posing heightened privacy and security concerns.
Genomics and Cybersecurity
Emergence of Vulnerabilities. Multiple vulnerabilities exist in regards to genomic data and exposure; several have already been introduced. Additionally, recurring risks include social engineering and exploits, genomic dossiers, DNA theft and genomic data theft. An additional, significant risk is genomic data and research falling into the wrong hands where biogenomic weapons could be created. Vulnerabilities associated with genomic data are great and will require enhanced security and privacy controls and in-depth defense to ensure data protection.
Social Engineering. History suggests nefarious actors can and will utilize the Internet for genomic data social engineering for re-identification purposes. Online genomic sites could be utilized to exploit data, including genomic gathering genealogy sites, online recreational genealogy sites and online genetic testing sites [7]. In addition to DNA-based genealogy online sites, genomic data can also be identified through various genomic projects funded via federal programs or academic endeavors.
MIT identified current genomic repositories that can be used, such as Ysearch to match Y chromosomes and surnames for genomic data re-identification [8]. These sites can be used for DNA theft. From here, an anonymous person could be easily identified using these online resources. Government and academic projects could also be used for genomic data identification.
Stanford University has detected an issue in identifying an individual’s genomic data through hacking a conglomeration of servers hosting genomic data sets [9]. One of the problems identified is server access control (also called beacons), where researchers are not assigned distinct accounts but rather share accounts. Annonymous users can query beacons for a specific gene and retreive information about the gene and the individual, thus compromising individual privacy.
Genomic Dossier. Online genomic data repositories can be a resource for nefarious actors looking to build a genomic dossier on an individual for maleficent purposes, including blackmail and discrimination. Dossiers are often used to shame and expose victims. Genomic dossiers could reveal sensitive medical and personal data, which, if publicly exposed, could leave the person feeling violated. Scenarios include cyber activism, political exploitation and potential blackmail, state-sponsored activity against another country and online campaigns waged by rogue online activist/hactivist groups targeting specific people for exploitation or exposure.
Currently, patient records are sold on the black market for as much as $500 to $700. However, the price increases when nefarious actors create dossiers on patients that include driver’s license numbers and passport information. The dossier then becomes a valuble commodity on the dark web due to the concatenation of data. Once genomic data is added to EHR systems and a breach occurs, the dossier value increases significantly with the addition of the stolen genomic data.
Genomic Database Theft. Amplified concerns exist regarding in-place security and privacy protections for databases and data warehouses storing genomic data. Many of these bioinformatic genomic systems were developed without security and privacy controls, and typically on a small-scale budget with limited staff. To help mitigate genomic databases from being compromised by nefarious actors and state-sponsored groups, the genomic system needs to facilitate a comprehensive security risk assessment at the High FIPS rating to determine and mitigate the security posture of the system. FIPS defines a high rating as a “severe or catastrophic” consequence to the company or patients should genomic data be exposed.
Nefarious actors will seek to exploit genomic databases for financial gain particularly when the in-depth data yields very sensitive information about people and their families. Sensitive information brings enhanced financial gain for the new data set. In addition, nefarious actors can facilitate genome mining, yielding ample information about genetic donors [10]. It is plausible to consider nefarious actors utilizing the black market and dark web as lucrative avenues for selling patient genomic data.
DNA Theft. As more companies offer DNA services and translation to genomic data, a rising concern exists about DNA theft and exposure. DNA theft is the taking or stealing of someone’s physical artifact, like a strand of hair, and then processing this sample to obtain DNA information about that person. Some examples where DNA theft would be performed may be for paternity testing, political sabbatoge and creation of personalized bioweapons against an individual.
Currently, only a few states have laws to prevent DNA theft and most are limited, treating it as a misdemeanor [11]. Therefore, most victims will have little recourse, according to several law journals, in obtaining judicial relief when victimized. DNA theft is difficult to track and can easily be facilitated with an online genomic website where a person purchases the DNA kit and then provides the obsconded DNA item from the victim. In a short matter of time, the DNA thief receives the genomic results.
Biogenetic Weapons. Mounting concerns exist with respect to advancing technology in processing, correlating and understanding genomic data. Precision medicine and pharmogenetics will undoubtedly provide vast amounts of information on genomic data, which could be precarious in the wrong hands. Dartmouth College provided an in-depth analysis explaining how advancing technology and genomic data could help in creation of biogenetic weapons [12]. Creation of such weapons can be customized based on new research, and future research provided from both PMI and pharmacogenomic environments and weapons can be individually specific.
As scientists, researchers, doctors and pharmacists learn more about DNA, new knowledge will evolve about how DNA works, which could then be utilized for DNA weaponization or creation of biogenetic weapons. No doubt, the genomic data will reside on a genomic health IT system or pharmacogenomic system warranting enhanced security and privacy controls. State sponsored and organized crime groups will be able to either pilfer or pay on the black market for this type of data. Particular emphasis needs to be placed around pharmacogenomic data as pharmaceuticals try to create medicines for specific genomic data types. The data created from pharmacogenomics ought to be treated as a FIPS 199 rated high system as well.
Another concern will include rogue pharmceutical companies in foreign countries with little government regulation. Currently, these pharmaceutical entities create medicines with questionable additives and engage with rogue organizations and corrupt governments. As pharmacogenomics ramps up in these foreign countries,
there will be little or no regulation on the creation of pharmacogenomic medications, which could have severe consequences. Nations are already experiencing loss of life due to medicines sent from these types of pharmeceutical companies. Current examples of questionable narcotics include bathsalts, heroin laced with phentanol or carfentanil. According to news reports, the U.S. Drug Enforcement Administration (DEA) surmises the fentanyl-type drugs are coming from pharmaceutical companies in foreign countries, and it is working to curtail their use [13].
Looking at this problem in regards to pharmacogenomics, serious concerns exist about further creation of dangerous drugs or worst-case scenario bioweapons or life-ending pandemic illness due to modified DNA from rogue pharmacogenomic facilities in other nations. Data and activities faciliated from these facilities will warrant government regulation and reviews. Additionally, pharmacogenomic data in the United States must receive enhanced protection to ensure it does not fall into the wrong hands.
Footnotes
- [1] Phenomics is “the systematic study of phenotypes on a genome-wide scale, by integrating basic, clinical and information sciences” and is also concerned with the characterization of phenotypes (phenome), which are characteristics of organisms arising via the interaction of the genome with the environment [4] (Source:http://www.humpath.com/spip.php?article11941).
- [2] Deidentification is the process undergone to ensure that a person’s identity can no longer be connected back to the original data source.
- [3] “A distributed denial-of-service (DDoS) attack is one in which a multitude of compromised systems attack a single target, thereby causing denial of service for users of the targeted system. The flood of incoming messages to the target system essentially forces it to shut down, thereby denying service to the system to legitimate users” (Source: http://searchsecurity.techtarget.com/definition/distributed-denial-of-service-attack).
References
- https://ghr.nlm.nih.gov/primer/precisionmedicine/definition
- Payne, Thomas H. et al. “Report of the AMIA EHR 2020 task force on the status and future direction of EHRs.” Journal of the American Medical Informatics Association. May 29, 2015. http://jamia.oxfordjournals.org/content/early/2015/08/14/jamia.ocv066.
- http://www.statewatch.org/news/2015/may/usa-crs-geomonic-data.pdf
- https://www.genome.gov/27026588/informed-consent-for-genomics-research/
- July 18, 2003: HIPAA Authorization for Research. National Institutes of Health
- http://www.statewatch.org/news/2015/may/usa-crs-geomonic-data.pdf
- Michael Snyder. “Genomics and personalized medicine: what everyone needs to know.” Oxford University press. 2016
- https://www.technologyreview.com/s/509901/study-highlights-the-risk-of-handing-over-your-genome/
- Jennie Dusheck. “Stanford researchers identify potential security hole in genomic data sharing network.” 2015. Retrieved from https://med.stanford.edu/news/all-news/2015/10/standford-researchers-identify-potential-seuciryt-hole-in-genmic.html.
- William Ferguson, 2013. “Attacked database prompts debate about genetic privacy: Experts urge transparency and new regulations to protect DNA donors.” Scientific American, 2013, http://www.scientific.american.com/article/a-hacked-database-prompts.
- Elizabeth Joh, “DNA Theft: Recognizing the crime of nonconsensual genetic collection and testing.” Pages 665-700, Boston University Law Review, Vol 91, Number 2, March 2011.
- Mackenzie Foley. “Genetically engineered bioweapons: A new breed of weapons for modern warfare.”2013. Retrieved from http://dujs.dartmouth.edu/2013/03/genetically-engineered-bioweapons-a-new-breed-of-weapons-for-modern-warfare/#.V7EmpZgrKUk.
- www.cnn.com/2016/08/04/healht/elephant-tranquilizer-carfentanil-herion. Article written by Nadia Kounang and Tony Marco – “Heroin laced with elephant tranquilizer hits the streets.” Aug 25, 2016

